

TL;DR : Le RAG (Retrieval-Augmented Generation) est une technique qui permet aux grands modèles de langage (LLM) de puiser dans des bases de connaissances externes et à jour avant de générer une réponse. Résultat : des réponses plus fiables, factuelles, et contextuelles, qui combattent efficacement les fameuses « hallucinations ».
Vous avez déjà discuté avec un chatbot qui invente des faits ou un LLM qui ignore les événements des dernières 24 heures ? Frustrant, n’est-ce pas ? C’est parce que ces modèles, aussi brillants soient-ils, fonctionnent en vase clos, avec les seules données de leur entraînement initial. Imaginez maintenant que vous donniez à ce cerveau surpuissant un accès direct et en temps réel à la bibliothèque de votre entreprise, à Internet ou à n’importe quelle base de données fiable. C’est exactement ce que fait le RAG (Retrieval-Augmented Generation). Loin d’être un simple acronyme technique de plus, c’est la révolution discrète qui est en train de rendre l’IA générative vraiment utilisable et fiable en entreprise. Accrochez-vous, on décrypte tout.
🧠 Comprendre le RAG en 2 minutes : L’IA avec un accès bibliothèque
Pour saisir l’essence du RAG, il faut d’abord comprendre la limite fondamentale des LLM comme GPT-4 et ses concurrents.
Le problème de base : les LLM, des génies amnésiques
Un grand modèle de langage est entraîné sur un corpus de données gigantesque, mais figé dans le temps. C’est comme un étudiant incroyablement intelligent qui aurait lu des milliards de livres jusqu’à une certaine date (par exemple, début 2023), mais qui n’aurait plus jamais ouvert un livre depuis.
Conséquences :
- Le savoir devient obsolète : Le modèle ignore tout ce qui s’est passé après sa date « d’examen final ».
- Il n’a pas accès à vos données privées : Il ne connaît rien de vos documents internes, de votre base de clients ou de vos procédures spécifiques.
- Il peut « halluciner » : Face à une question dont il n’a pas la réponse, il peut parfois inventer une réponse qui semble plausible mais qui est complètement fausse. C’est le plus gros frein à son adoption pour des tâches critiques.
La solution RAG : connecter le cerveau du LLM à une source de vérité
Le RAG, introduit pour la première fois dans un article de recherche original de Meta AI en 2020, est une architecture qui vient corriger ces défauts. Au lieu de répondre directement, le système RAG va d’abord chercher (retrieve) des informations pertinentes dans une source de données externe (la vôtre !). Ensuite, il augmente la question initiale de l’utilisateur avec ces informations fraîches et contextuelles. Enfin, il transmet le tout au LLM pour qu’il génère une réponse.
Une analogie simple : l’étudiant en examen à livre ouvert
Voyez le LLM de base comme un étudiant qui passe un examen de mémoire. Il est brillant, mais ne peut compter que sur ce qu’il a appris.
Le système RAG, c’est le même étudiant, mais cette fois, on l’autorise à consulter ses notes, le manuel du cours, et même une encyclopédie pendant l’épreuve (un examen « à livre ouvert »). Ses réponses seront non seulement plus précises et factuelles, mais il pourra même citer ses sources.
⚙️ Comment ça marche sous le capot ? Le processus en 3 étapes
Le processus du RAG peut sembler complexe, mais il se résume à une séquence logique en trois temps.
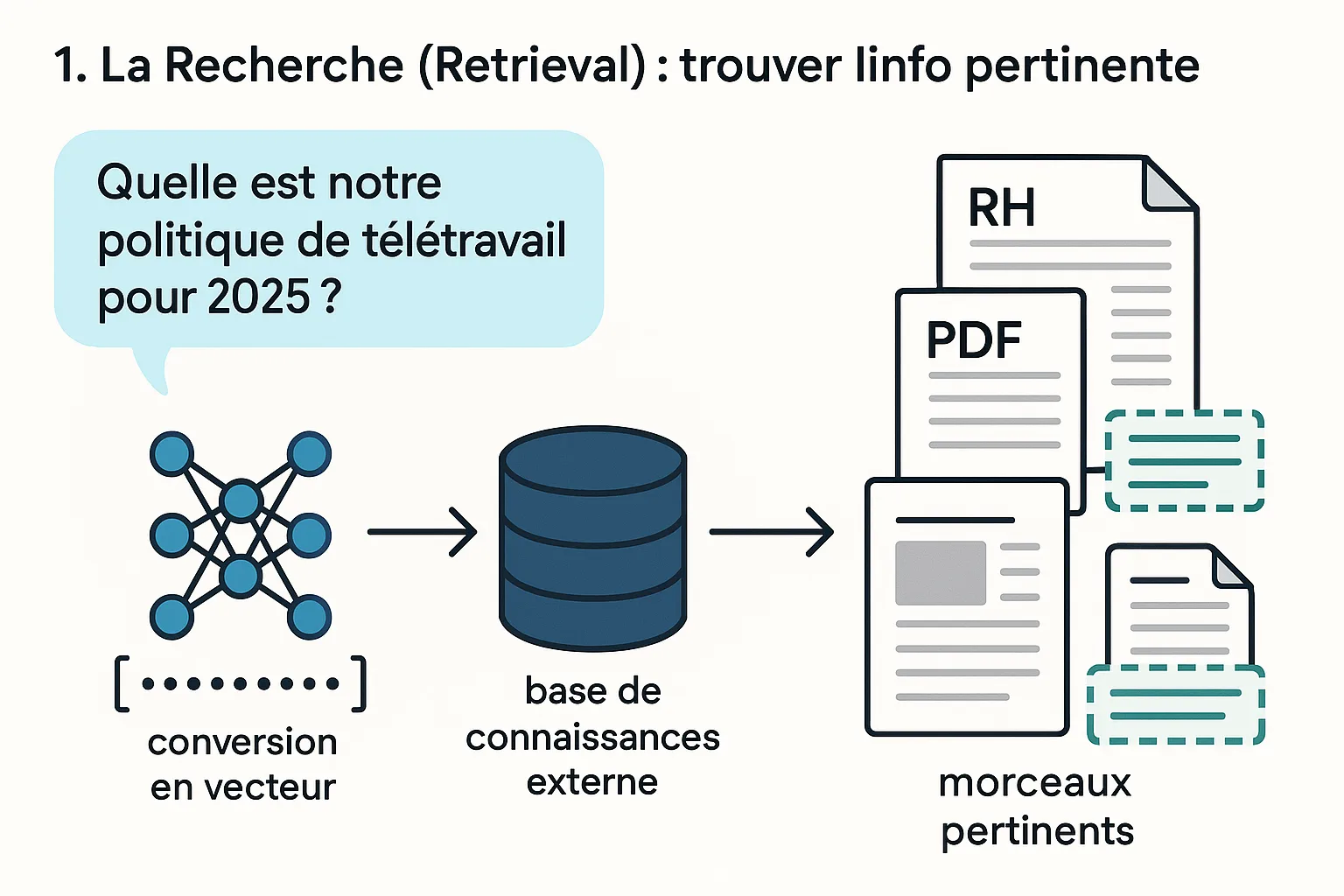
1. La Recherche (Retrieval) : trouver l’info pertinente
Quand vous posez une question (« Quelle est notre politique de télétravail pour 2025 ? »), le système RAG ne l’envoie pas directement au LLM. D’abord, il convertit votre question en un format numérique (un vecteur) et l’utilise pour interroger une base de connaissances externe que vous avez définie. Cette base peut contenir vos documents RH, des PDF, des pages de votre intranet, etc. Le système recherche les « morceaux » (chunks) de texte les plus pertinents sémantiquement par rapport à votre question.
2. L’Augmentation : enrichir le prompt
Une fois les passages les plus pertinents trouvés (par exemple, le paragraphe sur la nouvelle charte de télétravail), le système les injecte dans le prompt initial. Le prompt qui sera envoyé au LLM ne sera plus juste « Quelle est notre politique de télétravail pour 2025 ? », mais quelque chose comme :Contexte : [Voici le texte de la nouvelle charte de télétravail de 2025 : "..."] En te basant sur ce contexte, réponds à la question suivante : "Quelle est notre politique de télétravail pour 2025 ?"
3. La Génération : une réponse juste et contextuelle
Le LLM reçoit ce prompt « augmenté ». Il a maintenant tout ce qu’il faut : la question de l’utilisateur et les informations précises et fiables pour y répondre. Il peut alors générer une réponse de haute qualité, factuellement ancrée dans les documents fournis, au lieu d’inventer une réponse basée sur ses connaissances générales et potentiellement obsolètes.
Insight : La magie des « Embeddings » et des bases de données vectorielles.
Comment le système retrouve-t-il l’information « sémantiquement » pertinente ? Grâce aux embeddings. C’est un processus qui transforme les mots et les phrases en coordonnées dans un espace mathématique à plusieurs dimensions. Les textes qui ont un sens similaire se retrouvent proches dans cet espace. Votre question et les « chunks » de vos documents sont transformés en ces vecteurs. La recherche consiste alors à trouver les vecteurs de documents les plus proches du vecteur de votre question. Tout ce petit monde est stocké et géré dans des bases de données vectorielles comme Pinecone ou Weaviate, qui sont le moteur de l’étape de « Retrieval ».
🥊 RAG vs Fine-Tuning : Le match des titans de la personnalisation d’IA
Quand on veut spécialiser un LLM, deux grandes approches dominent : le RAG et le fine-tuning. Elles ne sont pas ennemies, mais répondent à des besoins différents.
Le Fine-Tuning : apprendre un nouveau comportement
Le fine-tuning (ou affinage) consiste à continuer l’entraînement d’un LLM pré-entraîné, mais sur un jeu de données plus petit et spécifique. Le but n’est pas tant de lui apprendre de nouvelles connaissances que de lui enseigner un style, un ton, ou une façon de structurer ses réponses.
- Quand l’utiliser ? Si vous voulez que votre IA parle comme votre service marketing, qu’elle adopte un jargon médical précis, ou qu’elle réponde toujours en format JSON.
Pour en savoir plus sur le fine-tuning vous pouvez lire notre article qui vous apprend comment fine-tuner votre propre LLM.
Le RAG : accéder à de nouvelles connaissances
Comme on l’a vu, le RAG ne modifie pas les « poids » du modèle. Il lui donne un accès à une connaissance externe en temps réel.
- Quand l’utiliser ? Quand vos informations changent souvent (politiques d’entreprise, stocks de produits, actualités) et que la traçabilité des sources est primordiale.
Tableau comparatif : Quand choisir quoi ?
| Critère | RAG (Retrieval-Augmented Generation) | Fine-Tuning |
|---|---|---|
| Objectif Principal | Accéder à des connaissances factuelles et à jour. | Adapter le style, le ton et le format du modèle. |
| Mise à jour des infos | Facile et instantanée (il suffit de mettre à jour la base de données). | Complexe et coûteux (nécessite de relancer un processus d’entraînement). |
| Coût | Généralement moins cher (pas de ré-entraînement de LLM). | Peut être très coûteux en ressources de calcul (GPU). |
| « Hallucinations » | Réduit drastiquement le risque, car basé sur des sources. | Peut réduire les hallucinations sur le domaine appris, mais pas les éliminer. |
| Traçabilité | Élevée. On peut citer les sources exactes utilisées pour la réponse. | Faible. Difficile de savoir pourquoi le modèle répond d’une certaine façon. |
| Compétences requises | Connaissances en architecture de données, bases vectorielles. | Connaissances en Machine Learning, préparation de datasets. |
L’approche hybride : le meilleur des deux mondes ?
De plus en plus, les experts réalisent que RAG et fine-tuning sont complémentaires. On peut très bien « fine-tuner » un modèle pour qu’il adopte le ton parfait de l’entreprise, ET le connecter via RAG à la base de connaissances interne. On obtient alors une IA qui non seulement sait quoi dire (grâce au RAG), mais qui sait aussi comment le dire (grâce au fine-tuning).
🚀 Le RAG en pratique : 4 cas d’usage qui changent la donne
Le RAG n’est pas qu’un concept théorique. Il alimente déjà des applications concrètes.
- 1. Les chatbots de service client qui ne disent plus de bêtises
Connecté à la base de produits, aux guides utilisateurs et à l’historique des tickets, un chatbot RAG peut répondre précisément aux questions des clients sur leur commande, les pannes, ou les caractéristiques d’un produit. - 2. L’aide à la recherche et à l’analyse de documents complexes
Pour les avocats, les chercheurs ou les analystes financiers, le RAG est un outil surpuissant. Il peut ingérer des milliers de pages de documents juridiques ou de rapports financiers et permettre à l’utilisateur de poser des questions en langage naturel pour en extraire des informations clés en quelques secondes. - 3. La génération de contenu ultra-personnalisé et factuel
Une agence de marketing peut utiliser le RAG pour créer des descriptions de produits. Le système puise dans les spécifications techniques (la source de vérité) pour générer un texte marketing engageant mais toujours factuellement correct. - 4. Les assistants personnels pour les employés (RH, IT, etc.)
Un « portail RH » conversationnel basé sur RAG peut répondre instantanément aux questions des employés sur leurs congés, leur mutuelle ou les notes de frais, en se basant toujours sur les documents officiels et à jour de l’entreprise.
🔬 Au-delà du RAG de base : les techniques avancées
Le domaine évolue à une vitesse folle. Le RAG « naïf » (simple recherche puis génération) laisse déjà la place à des approches plus sophistiquées pour améliorer encore la pertinence et la précision.
- Pre-retrieval : mieux préparer les données
Cela consiste à optimiser la façon dont les documents sont découpés (Chunking) et indexés. Par exemple, la technique HyDE (Hypothetical Document Embeddings) demande au LLM de générer une réponse « hypothétique » à la question de l’utilisateur, et c’est cette réponse (plus riche) qui est utilisée pour la recherche, améliorant la pertinence des documents trouvés. - Post-retrieval : filtrer et réorganiser les résultats
Après avoir récupéré un certain nombre de documents, on peut utiliser une étape de Re-ranking. Un modèle plus petit et spécialisé ré-ordonne les documents récupérés pour placer les plus pertinents en premier avant de les envoyer au LLM principal. Cela permet de réduire le « bruit » et d’améliorer la qualité de la réponse finale. - Le Self-RAG : l’IA qui s’auto-corrige
C’est une des avancées les plus passionnantes. Des frameworks comme Self-RAG apprennent au LLM à évaluer lui-même les documents récupérés. Il peut décider si un document est pertinent ou non, s’il a besoin de chercher plus d’informations, ou s’il doit utiliser un document plutôt qu’un autre pour générer sa réponse. Il devient un acteur actif du processus de recherche.
🔮 Le Futur du RAG : vers des IA encore plus autonomes et fiables
Le RAG n’est que la première étape. L’avenir s’annonce encore plus intégré et intelligent.
- Le GraphRAG : raisonner sur des données connectées
Au lieu de chercher dans des morceaux de texte isolés, le GraphRAG utilise une base de connaissances structurée en graphe (comme une carte mentale de vos données). Cela permet à l’IA de non seulement trouver des faits, mais aussi de comprendre et d’exploiter les relations entre ces faits, menant à des raisonnements beaucoup plus profonds. - Le RAG multimodal : au-delà du texte
Le futur du RAG inclura la capacité de chercher et de raisonner sur des informations issues de différents formats : texte, bien sûr, mais aussi images, graphiques, et même audio ou vidéo. - L’impact sur la fiabilité et la lutte contre les hallucinations
En rendant le processus de raisonnement de l’IA plus transparent et vérifiable, le RAG est notre meilleure arme actuelle contre le problème des hallucinations. Il transforme le LLM d’une « boîte noire » créative en un outil de raisonnement ancré dans des faits vérifiables. C’est la clé pour bâtir une IA de confiance.
🤔 FAQ – Vos questions sur le RAG
Est-ce que le RAG élimine complètement les hallucinations des IA ?
Non, mais il les réduit de manière spectaculaire. Une hallucination peut encore survenir si les documents de base sont eux-mêmes erronés, ambigus ou si le LLM interprète mal le contexte fourni. Cependant, en forçant le modèle à baser sa réponse sur une source concrète, on limite drastiquement sa tendance à « inventer ».
Faut-il des compétences techniques avancées pour mettre en place un système RAG ?
Mettre en place un RAG « maison » de A à Z demande des compétences en architecture logicielle et en science des données. Cependant, l’écosystème explose : des frameworks comme LangChain ou LlamaIndex, ainsi que des plateformes cloud (AWS Bedrock, Azure AI Search, Google Vertex AI Search), simplifient énormément le déploiement de systèmes RAG, les rendant accessibles à de plus en plus de développeurs.
Le RAG est-il sécurisé pour les données d’entreprise ?
Oui, c’est l’un de ses points forts. Contrairement au fine-tuning où vos données sont envoyées pour ré-entraîner un modèle externe, dans une architecture RAG bien conçue, vos données propriétaires restent dans votre infrastructure. Le LLM externe ne reçoit qu’un prompt contenant de petits extraits pertinents pour répondre à une question unique, sans jamais avoir accès à l’ensemble de la base de données. La gestion des accès peut être finement contrôlée.


